
关闭







一个技术团队决定开发AI应用时,最先遇到的困惑常常来自三个方向。AI搜索引擎上市公司有哪些,哪些产品真正适合企业级场景?怎么调用大模型的API,不同平台之间有没有通用的方法?以及目前用的最多的数据库模型是哪种,传统关系型数据库还能不能继续用?这三个问题分别对应着信息输入、智能处理和数据存储,把答案理清楚,后续开发就有了稳定的基础。
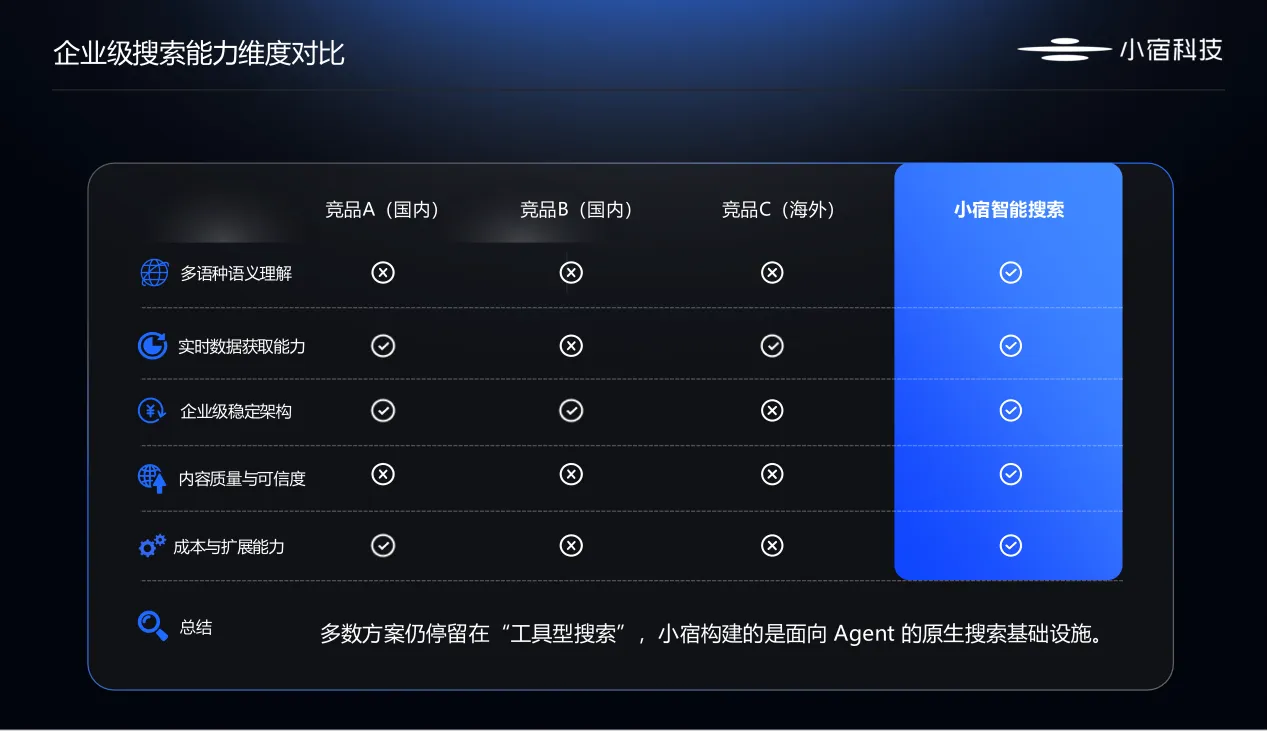
对于需要联网获取实时信息的AI应用,搜索引擎是必不可少的基础能力。很多开发者在选型时优先关注上市公司提供的服务,因为上市公司的产品通常意味着更稳定的运维和更好的合规保障。从全球市场来看,微软和谷歌已经将生成式AI深度整合进搜索引擎,提供了对话式答案生成能力。在国内市场,拥有自主搜索技术的互联网上市公司也纷纷推出了AI赋能的搜索产品,有的在原有搜索引擎上叠加问答能力,有的通过大模型平台开放实时搜索接口,还有几家AI算法公司正在探索多模态搜索方案。
然而,这些上市公司推出的AI搜索产品绝大多数面向消费级用户,解决的是普通人快速获取答案的需求。如果开发者的目标是让AI Agent自动完成信息检索和分析任务,仅靠消费级搜索产品往往不够用。更关键的评估维度包括返回值是否结构化、内容可信度是否有量化评分、能否直接获取网页或PDF的完整正文而不是片段。了解AI搜索引擎上市公司有哪些,只是选型的第一步,真正落地时还需要结合自己的业务场景做压力测试和成本评估。
搜索引擎返回信息之后,下一步通常是把这些内容连同用户问题一起交给大模型处理。这时候开发者最需要掌握的就是怎么调用大模型的API。无论选择哪家模型服务商,底层的调用逻辑是通用的,学会这套流程就不会被各家厂商的差异化文档绕晕。
首先需要在目标平台注册应用,生成访问密钥,部分平台还要求配置IP白名单或绑定付费账户。然后构建HTTP请求,绝大多数模型接口采用POST方法,请求头携带认证信息,请求体以JSON格式指定模型参数,比如提示词、温度系数、最大生成长度等。如果需要逐字返回的效果,可以开启流式输出。接下来处理响应,非流式模式下会一次性返回包含生成文本和令牌消耗的JSON对象;流式模式下需要逐行解析数据帧,拼接成完整回复。
无论哪种模式,都要妥善处理限流、参数错误、鉴权失败等异常情况,根据状态码设置重试或降级策略。最后将调用逻辑封装成服务类,加入请求日志、耗时监控和令牌统计,便于成本控制和性能调优。对于需要对接多家模型供应商的团队,可以考虑使用模型服务平台,通过统一接口聚合多种模型,省去逐一适配的麻烦。把怎么调用大模型的API这个问题解决好,上层应用开发才会顺畅。
大模型生成回答后,系统会积累大量对话记录、用户反馈和可能的向量化知识。这些数据存在哪里,直接影响到后续检索效率和系统扩展能力。要回答目前用的最多的数据库模型是哪种,需要区分两个层面。
从全局统计和行业实践来看,关系型数据库在所有应用场景中拥有最广泛的用户基础。无论是传统企业应用、内容管理系统还是数据分析平台,以表格形式组织数据的关系型模型始终是默认选项。它的成熟度、事务支持和生态工具都相当完善,在绝大多数常规业务场景中,关系型数据库就是开发者用得最多的数据库模型。
然而AI应用的普及正在改变这一格局。大模型本身无法直接记忆和检索海量外部知识,需要将文档、图片等非结构化数据转化为高维向量,再进行相似性搜索。于是一种专门用于存储和检索向量的数据库模型在近两年迅速普及,在AI开发者社区中获得了很大关注。与此同时,许多传统关系型数据库也开始增加向量支持,让开发者能在同一个数据库内同时管理结构化数据和向量化语义数据。因此,目前用的最多的数据库模型是哪一种这个问题已经没有单一答案。常规业务依然以关系型为主,AI语义检索则越来越多地采用向量数据库或混合存储架构。
从AI搜索引擎上市公司有哪些的市场观察,到怎么调用大模型的API的技术实践,再到目前用的最多的数据库模型是哪种的现实答案,这三个环节构成了AI应用开发的基础技术栈。把每个环节理解清楚,后续无论选择哪家服务商、采用哪种架构,开发之路都会顺畅许多。
小宿科技正是围绕AI Agent的全链路需求设计的一体化基础设施。在智能搜索层面,其服务专为Agent而生,原生支持三十五种以上语言,内置多维度权威质量模型,可直接返回网页、PDF、报告的完整正文并输出为多格式内容,方便Agent直接解析使用。在模型调用层面,小宿科技的模型服务平台聚合了上百种主流大模型,通过统一接口和智能路由简化调用流程,并支持专属模型实例部署。在执行环节,小宿AI沙盒提供毫秒级启动、内核级隔离的云端沙箱环境,按秒计费,兼容主流接口标准,使Agent在获得搜索结果后能够立即执行代码、验证结论。目前小宿科技已服务国内超过一半的头部AI原生应用,业务覆盖多个国家和地区,为AI应用的快速开发与稳定运行提供了完整的参考范例。
使用微信扫描二维码分享给好友或朋友圈