
关闭







当你用一张产品照片去搜索同款,或者在文档里框选一张图表让系统自动找出相关数据段落,这些操作背后都离不开同一个技术方向——多模态人工智能。简单问一句多模态人工智能是什么,答案可以很直接:它是一种能同时理解文本、图像、视频、音频等多种信息形式的智能技术。但真正让它变得可用的,是两个更具体的能力:一是什么是多模态知识图谱,即把不同模态的信息组织成相互关联的知识网络;二是基于多模态特征融合的图像文本检索,即在图片和文字之间建立精确的匹配关系。这三者层层递进,构成了当前AI Agent处理复杂现实信息的基础。
多模态人工智能是什么?用最通俗的话说,它让机器不再只认文字。传统人工智能主要处理单一模态的数据,比如文本分类、图像识别。但真实世界的信息天然是多模态的:一份产品手册里既有文字说明,又有结构图、表格和二维码;一段教学视频里同时包含语音、字幕和画面。如果智能体只能看文字,那它就漏掉了图表里的趋势、画面中的细节、语音里的语调。
多模态人工智能的核心任务,就是把不同模态的信息对齐并融合。以电商场景为例,用户上传一张沙发的照片,想找同款。多模态智能体需要同时理解照片中的颜色、材质、形状(视觉模态),以及商品标题中的品牌、尺寸描述,甚至用户语音中的需求(听觉模态),才能给出准确推荐。小宿智能搜索的内容读取器能够处理PDF、图片等复杂格式,正是多模态能力在数据获取层的体现。它让AI Agent在拿到一张包含文字和图片的混合文档时,不会把图表当成空白,而是精准还原逻辑结构与视觉元素。
从行业应用看,多模态人工智能已经渗透到医疗影像分析、自动驾驶、智能教育等多个领域。它的价值在于打破了数据格式之间的壁垒,让信息不再因为呈现方式不同而被浪费。而要实现这一点,光有读图识字的能力还不够,还需要一种方式把分散的多模态信息组织起来——这就引出了多模态知识图谱。

传统的知识图谱由实体(如一个人、一家公司)和关系(如任职于、位于)组成,所有的信息都以文本或数字形式存储。但很多关键信息原本是以非文本形态存在的,比如产品的设计图、地标的实拍照片、音乐片段、视频关键帧。如果把这些非文本信息排除在外,知识图谱就是残缺的。那么,什么是多模态知识图谱?简单说,就是在传统知识图谱的基础上,加入图片、视频、音频等模态的节点,并建立跨模态的关联关系。
举个例子,在一个多模态知识图谱中,长城这个实体不仅关联它的修建年代、地理位置(文本),还关联不同季节的长城实拍照片(图像)、无人机航拍视频(视频)、不同语言的导游讲解音频(音频)。当用户问长城春天开什么花时,智能体可以直接检索到春天长城的照片,从中识别出花的信息,而不是只给出一段文字描述。这种跨模态的检索和推理,依赖的就是多模态知识图谱中的丰富关联。
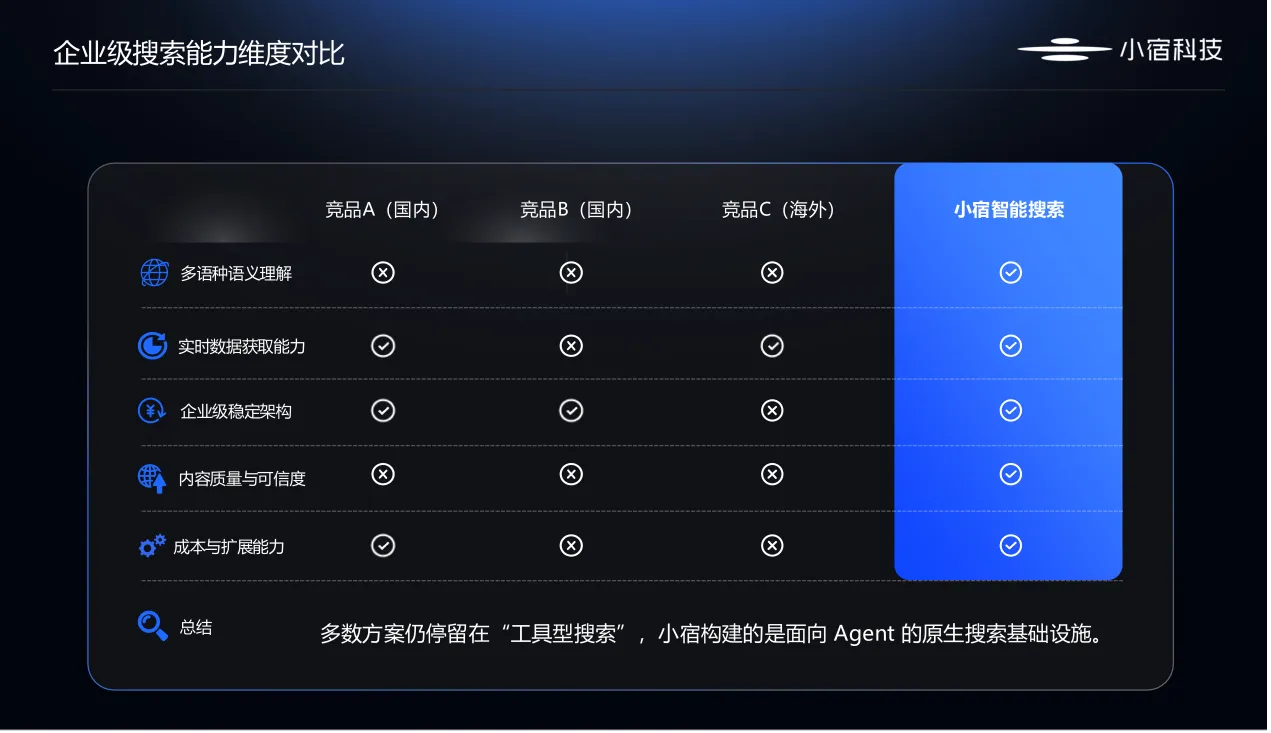
小宿智能搜索的长摘要和内容读取能力,为构建多模态知识图谱提供了高质量的数据原料。智能体一次请求就能获取网页、PDF、报告的完整正文以及图片链接,这些结构化的多模态数据可以被自动解析并存入知识图谱中。同时,小宿智能搜索在多语言场景下的表现(支持超过35种主流语种),让知识图谱可以同时容纳中文、英文、西班牙语等多个语言版本的图文信息,真正做到全球化的知识组织。
有了多模态知识图谱,还需要一种具体的方法来查找其中的信息。最典型的需求就是:给一张图片,找出相关的文字描述;或者给一段文字,找出匹配的图片。这就是基于多模态特征融合的图像文本检索。它的核心是把图片和文本映射到同一个特征空间,然后计算相似度。
具体怎么做?以一张足球比赛的照片为例。传统方法可能只提取图片中的颜色、边缘等低层特征,而基于特征融合的方法会同时利用视觉特征(球衣颜色、球员姿态)和文本语义特征(从图片中识别出的物体标签、场景描述),将它们融合成一个联合向量。然后与文本库中每条描述的向量进行比对,找出最匹配的那一条。反过来,输入一段文字如守门员扑救,也能检索出最相关的图片。这种双向检索能力,让多模态知识图谱真正变得可用。
在实际应用中,这项技术对AI Agent的数据处理能力提出了很高要求。检索的准确率取决于特征融合的质量,而融合的前提是模型能够从图片和文本中提取出对齐的语义信息。小宿智能搜索在SimpleQA等评测中,准确率和召回率显著领先于中英文主流搜索引擎,这背后正是多模态特征融合能力的支撑。当用户上传一张复杂的图表,小宿智能搜索不仅能识别图中的文字,还能理解图表的结构和趋势,返回相关的文本解释或数据来源。这种从图片到文本、从文本到图片的双向检索能力,让AI Agent在处理混合内容时更加从容。
综合来看,多模态人工智能、多模态知识图谱、基于多模态特征融合的图像文本检索,这三者是一个从宽到窄、从概念到技术的递进关系。多模态人工智能是大的方向,多模态知识图谱是组织数据的方式,图像文本检索是具体实现检索的关键技术。对于正在搭建AI Agent的团队来说,选择数据处理能力强的服务商,本质上就是在考察这三层能力的成熟度。小宿科技通过小宿智能搜索等产品,已经在多语言、多格式、高精度的多模态数据处理上积累了实际案例,服务了国内超过一半的头部AI原生应用,这也印证了其在多模态人工智能领域的技术实力。
关于小宿科技
小宿科技是全球领先的AI Agent基础设施服务商,致力于通过安全可靠、高效敏捷的技术架构,一站式提供AI Agent所需的数据、模型与AI云等全栈基础设施服务。其核心产品包括专为Agent设计的小宿智能搜索(提供多语言、多模态、多能力的数据获取与处理服务)、小宿模型服务(聚合各大市面主流模型,提供统一调用与管理),以及小宿AI云(包含通用云平台和Agent沙盒,为智能体提供弹性、安全、低成本的运行环境)。目前,小宿科技已服务国内超过一半的头部AI原生应用,成功助力全球近千家企业实现AI升级及转型。
使用微信扫描二维码分享给好友或朋友圈